BD – Isilon Multi-protocol access & Hadoop
Surely a scale out NAS array has little to do with Hadoop?
Why not just use commodity servers stuffed full of disks for your Hadoop needs?
Well, as it happens, Isilon has a great offering in Enterprise level Hadoop solutions By “Enterprise level Hadoop”. I mean that once a business decides it needs to put Hadoop into production, it requires all of the usual business processes surrounding a mission critical application. Typical Enterprise requirements are data protection, backup, snapshots, replication, high availability and security. With Isilon, not only do you get those Enterprise level features but you also get native HDFS support just like Isilon supports SMB, NFS, FTP, NDMP and Swift protocols.
Well what does that actually mean when put into production use?
Most high end NAS solutions offer simultaneous access to the same pool of data via say an NFS share and a SMB share.

You can look at the share in Windows Explorer (left hand image), type in ‘ls’ on the NFS share (right hand image) and you have access to the same data. You can read or write the data via any of the supported protocols assuming of course you have the appropriate file permissions.
Isilon, being a mature, Enterprise level NAS device, also provides all of the typical file sharing protocols and features but adds more!
Isilon supports the native HDFS protocol in the same manner. If you look at the share in Windows Explorer or do a ‘hdfs dfs –ls /’ it will look the same!
The screen grab below shows the output from “hdfs dfs –ls” of the same directory as those shown above in Explorer and NFS
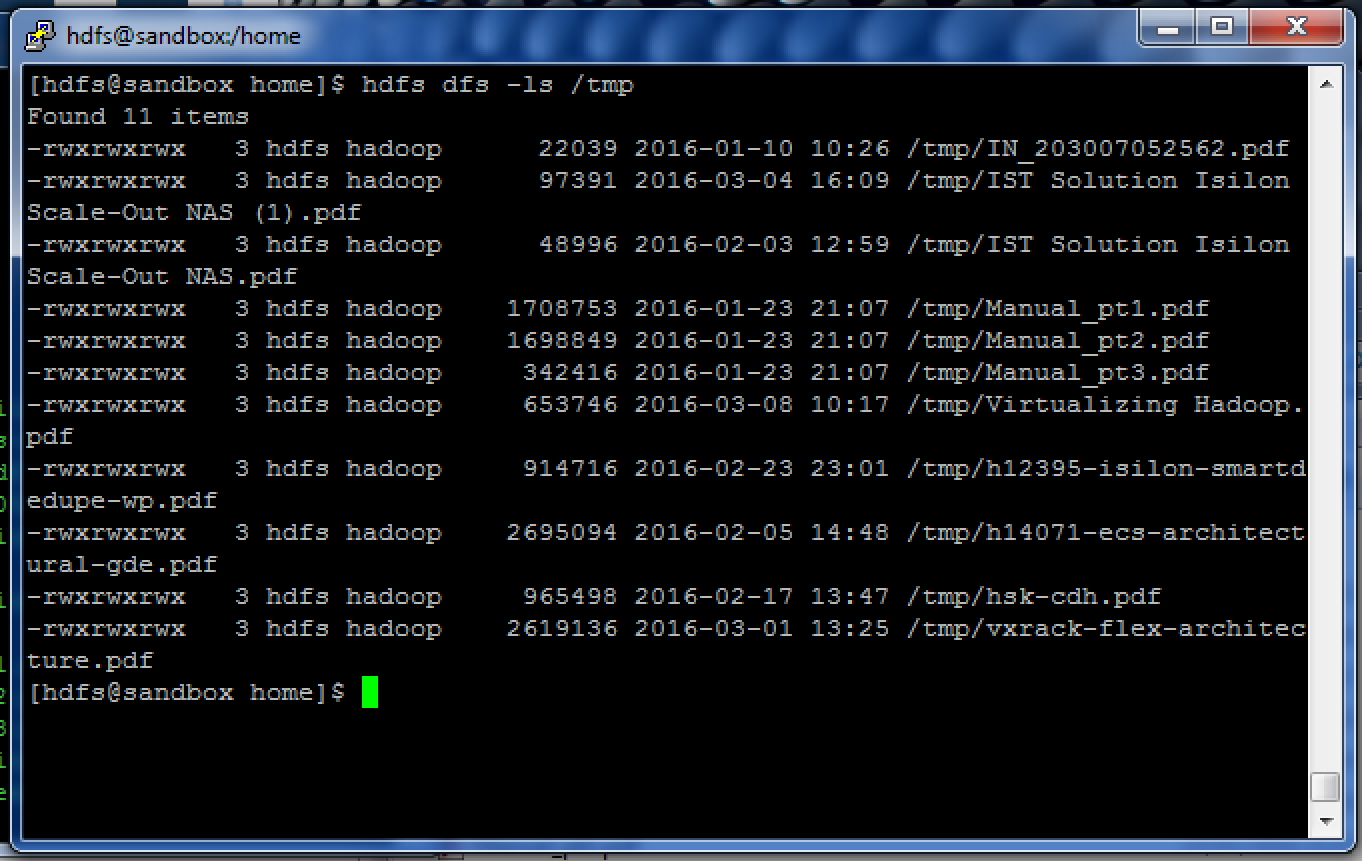
This means that you can simply upload your data into your Isilon based Hadoop cluster using traditional IP based protocols and then run Hadoop queries against it straight away. There is no need to move the data, no translation, no post processing, it is just immediately available via the other protocols. Most importantly you dont need the default triple replication of the data thereby saving a huge amount of disk space. Obviously all the usual Hadoop ingest processes such as Sqoop or Flume and also Hortonworks data Flow (HDF) can also be used but the traditional IP based protocols such as SMB and NFS are well understood and have been used to share data for years.
How can this make your life easier?
In this example workflow, you have some logs from a web server writing to an NFS share. You want to run some Hadoop jobs against the data and then view the results via a windows client. You can do this in the traditional manner and have to copy the data into HDFS and out again but with Isilon it is far simpler.
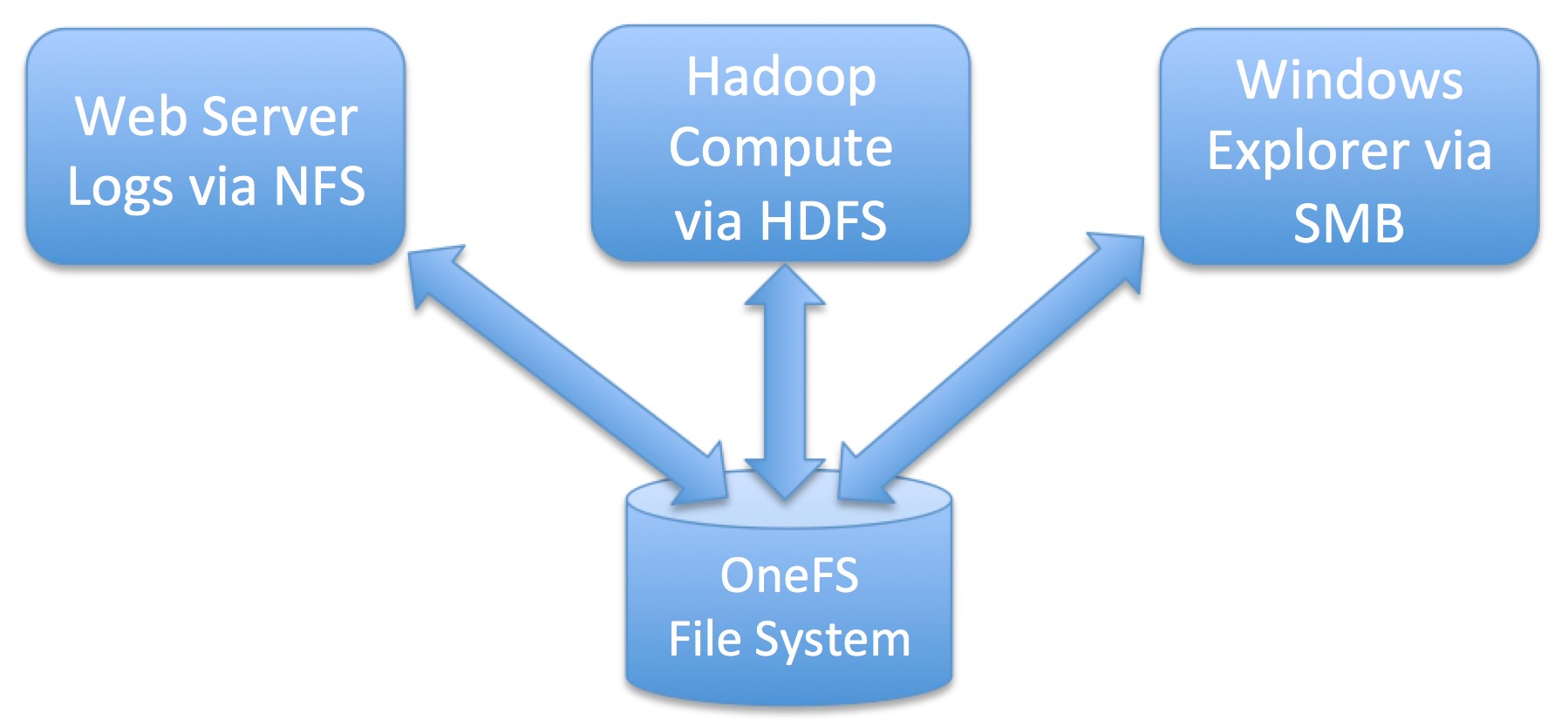
The diagram above logically shows the following workflow.
- You write your Web server log files into an NFS share
- You then run Hadoop queries directly against them over HDFS
- The results from the Hadoop job are written directly into a directory via HDFS which is then also available via an SMB share to make it easy to view the results straight away as a Windows user.
There is no extra moving of data in/out of HDFS, no transferring of the results to another location. It is available via any of the protocols as soon as it is written to the underlying OneFS file system. (OneFS is the operating system that runs on each node in the Isilon cluster providing the shared single file system namespace across all nodes.)
How does Isilon achieve this very useful functionality?
Each node in the Isilon Cluster runs a HDFS daemon process that responds to HDFS protocol requests as both a NameNode and a DataNode. Those requests are “translated at wire speed”, just like any other supported IP protocol, into the associated actions/results onto the Isilon OneFS Posix file system. The diagram below shows a high level view of what is going on for well know standard IP based protocols

The IP protocol talks to the Isilon via a service running on a specified standard IP port. An associated service running on the protocol specific port translates the commands/data into the appropriate action onto the underlying file system. Isilon has created an HDFS protocol translator service that responds to NameNode and DataNode requests on the default port 8082. Other HDFS services such as https and webHDFS use different port numbers.
The diagram below logically shows a 4 node Isilon cluster running the HDFS daemon on each node and acts like both a NameNode and a DataNode for all of the data in the pool.
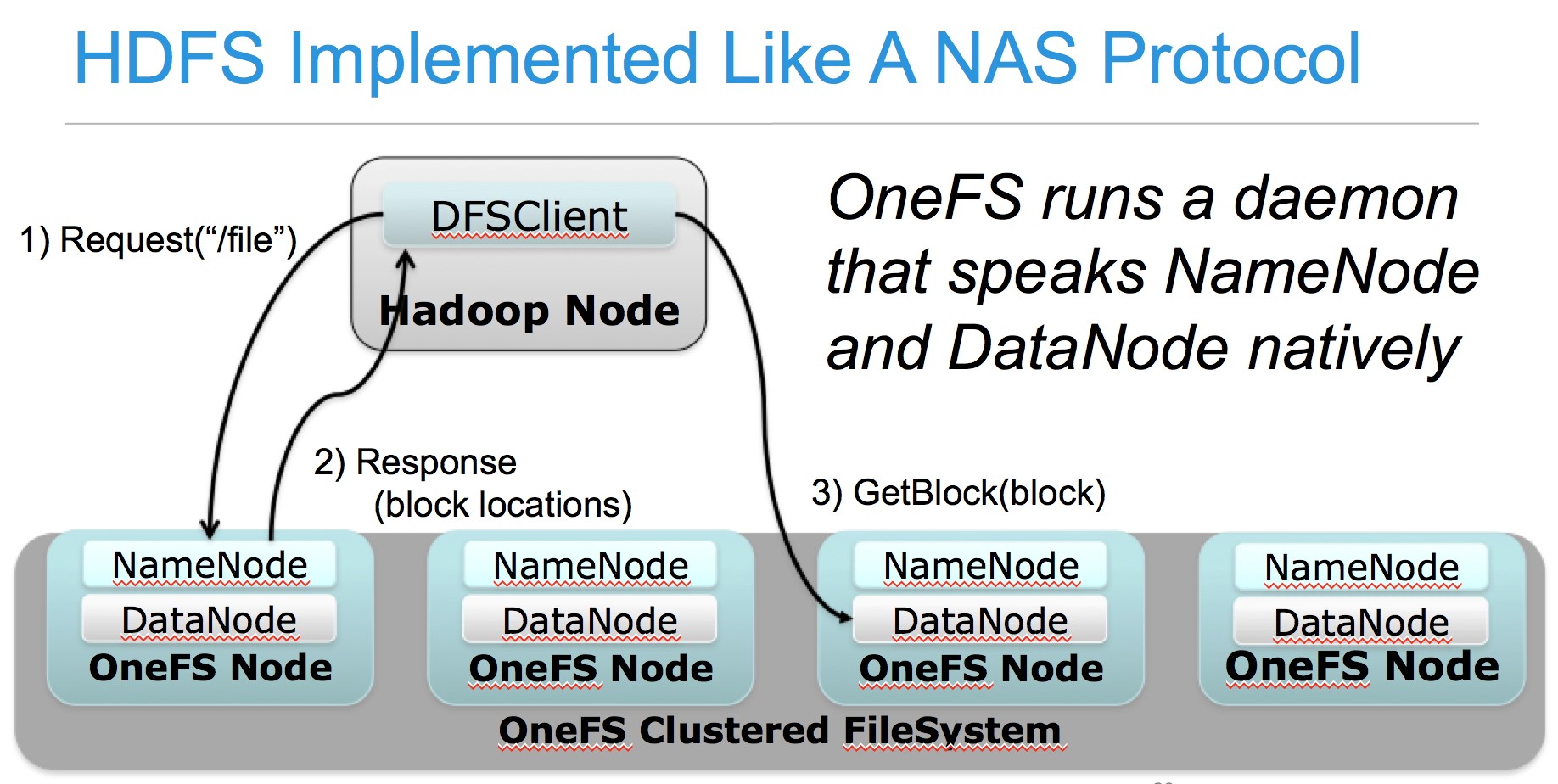
- The Hadoop worker node, running the standard HDFS Client code, connects to the NameNode to request the location of a block/file.
- NOTE: There is no specific code or plugin required on any client as Isilon runs a fully HDFS compliant service. You just use the default HDFS software provided by an Apache Hadoop distribution.
- The Isilon NameNode service provides a compliant API response with the IP addresses of three DataNodes that have access to the data requested (on Isilon, all of the nodes in the pool or zone have access to all of the data)
- Isilon also supports “rack awareness” to return the most appropriate nodes IP addresses.
- The compute worker node then connects to the Isilon DataNode service running on one of the nodes specified by the NameNode to request the data.
- The selected Isilon node collates the data from the OneFS file system and returns it to the worker node.
In the above example, the NameNode listed in the core-site.xml file is the fully Qualified Domain Name (FQDN) of the SmartConnect IP address of the Isilon.
SmartConnect is an Isilon software feature that does IP load-balancing to spread the client connections from the Hadoop worker nodes across the nodes in the Isilon cluster.
Using Isilon for the underlying HDFS file system for your Hadoop compute cluster means that in a 10 node Isilon cluster there are 10 NameNodes and 10 DataNodes to support the Hadoop Compute requirements. There is no need for Secondary NameNodes or HA NameNodes as the primary service runs on every Isilon node. Isilon does not require any tuning of the memory allocation for metadata store on the name node as that function is built into the design of the Isilon node and the OneFS file system. Obviously this solution provides an extremely high level of NameNode resilience!
Isilon adheres to the HDFS protocol standards and is thoroughly tested for each Hadoop release. For example, EMC Isilon’s HDFS protocol is tested using the same 10,000 tests that HortonWorks uses for each of its new releases. It is backwards compatible so you can run production on a stable version and then spin up a new version, read the same data and test it out before committing production to the new version of code.
After explaining the Isilon HDFS solution to a customer a little while ago, they suggested that a good way to describe it was that “Isilon provides a first class file system for HDFS”
In summary, some of the benefits of using multi-protocol access on Isilon as your HDFS storage layer are as follows:
- Multiple Protocol access to your data without any moving/copying of data
- Multiple versions of Apache based Hadoop distributions supported
- Different Hadoop distributions can have access to the same data (read only for simultaneous access). You can try out a distribution and then go back to your original supplier if it does not work out.
- Different Versions of Hadoop can have access to the same data without copying it.
- Note: There are a few distribution and version specific issues to be aware of such as adding different users (ambari_qa or cloudera’s manager) but fundamentally you can provide access to the data for different distributions/versions.
- You can scale compute and storage independently. Need more capacity? add another Isilon node, need more compute? add another worker node.
- You don’t need to replicate the data 3 x to provide data protection. Isilon is far more efficient, using FEC to protect the data. This typically provides up to around 80% usable/raw disk saving on rack space, power and cooling.
There are a number of other major benefits from using Isilon as the HDFS data store. I will describe some of them in future posts.
For more immediate queries please see the EMC Isilon Big Data Community page.
